Управление данными
Важная сторона автоматизации управления гостиницами — это управление данными.
В основе современных систем управления гостиницами лежат мощные базы данных, позволяющие аккумулировать и хранить детальную информацию по работе гостиницы и её взаимоотношениям с каждым гостем.
И если автоматизацию процессов функционирования гостиницы можно назвать обязательным условием для успешной работы гостиницы, то эффективное использование собранных данных является ключевым фактором для достижения гостиницей конкурентного преимущества на рынке.Накопленные данные становятся бесценным капиталом для гостиницы. Базы данных
постояльцев позволяют детально изучать целевой рынок гостиницы, прогнозировать спрос на услуги, проводить эффективную маркетинговую политику. Закрытость информации, характерная для рыночных отношений, не позволяет с системных позиций подойти к проблеме переработки данных, но дает возможность использовать ее более тщательно и эффективно.
Любое производство связано с потоками внутренней и внешней информации. Среди многообразия поступающих сведений менеджеру для принятия решения нужны лишь строго определенные, а все остальные представляют собой информационный шум. Большая часть информации возникает не там, где в ней нуждаются; разрешение проблемы коммуникации оказывает влияние на скорость поступления информации и ее своевременность, что способствует более эффективной работе предприятия. Этот далеко не полный круг проблем выявляет необходимость построения специальной управляющей информационной системы, которая бы способствовала их оптимальному решению.
Для принятия любого решения приходится проводить сложные и трудоемкие исследования, связанные с анализом разноплановой информации Современная вычислительная техника и программные средства являются основой всей оперативной деятельности, прогнозирования и контроля. Комплексное изучение информационных потоков требует анализа крупных массивов сведений коммерческого и статистического характера.
Специалистам требуется не просто информация о некоторой проблемной ситуации, а недостающее знание. Чтобы решить проблему, информационная система должна обладать знаниями о конкретных предметных областях, а также о том, как связаны между собой отдельные факты и как выявленные зависимости могут использоваться при различных обстоятельствах. Такие системы становятся интеллектуальными. Действительно, в процессе решения задач, которые характеризуются отсутствием, противоречивостью и нечеткостью данных, альтернативностью возможных путей решения возрастает значение не количественных методов, а эвристического опыта. В таких случаях применяются информационно-экспертные системы, которые, по сути становятся системами принятия решений. Они воспроизводят рассуждения экспертов при решении задач, в которых первостепенное значение приобретает извлечение знаний из накопленной фактографии. Использование возможностей таких систем
в исследованиях позволяет специалистам оперативно ориентироваться на внешнем и внутреннем рынках, чутко реагировать на изменения потребительского спроса.
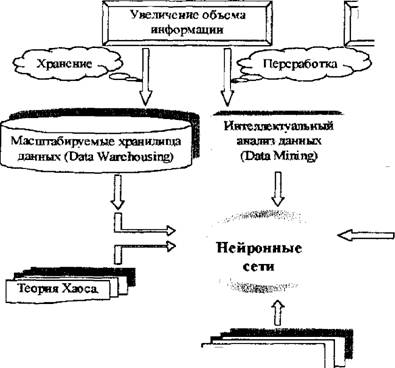
Интеллектуальный анализ данных (Data Mining). Острая конкурентная борьба, стремление компаний получать отдачу от инвестиций в информационные технологии, рост числа сотрудников, принимающих решения, стимулировали активное развитие новой области информатики — технологии интеллектуального анализа данных (ИАД, или Data Mining — DM). Ее основное назначение — автоматизированный поиск ранее неизвестных закономерностей в базах данных деятельности компаний, и использование добытых знаний в процессе принятия решений. С помощью DM можно выявить, например, профиль потребителей
данного товара, предотвратить махинации с кредитными карточками или предсказать изменение ситуации на рынке. Структура DM приведена на рис. 6.
I Data Mining
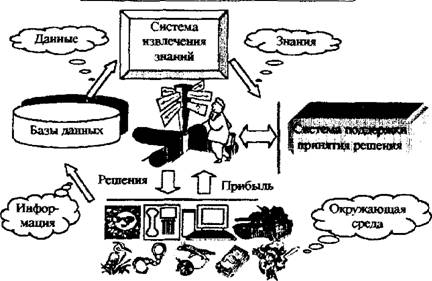
Рис. 6. Data Mining — извлечение знаний из данных.
DM — удачный пример того, как информационные технологии помогают компаниям быстро и относительно легко производить анализ накопленных данных и по его результатам
принимать мотивированные решения.
Системы DM реализуют новую форму анализа данных, основанную на интеллектуальном подходе. Они просматривают горы информации и автоматически выявляют скрытые правила и закономерности, которые могут быть неочевидными для пользователя. Полученные знания помогают оптимизировать бизнес-процессы в самых ответственных областях
деятельности — маркетинге, производстве, обслуживании клиентов. DM как систему доставки информации необходимо включать в информационные системы уровня предприятия1.
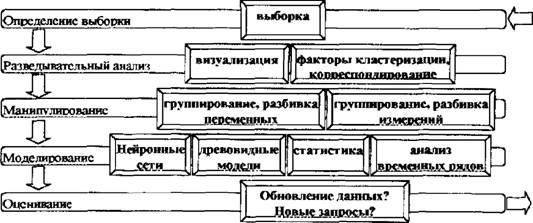
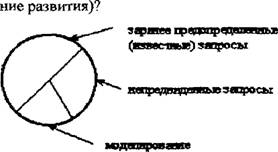
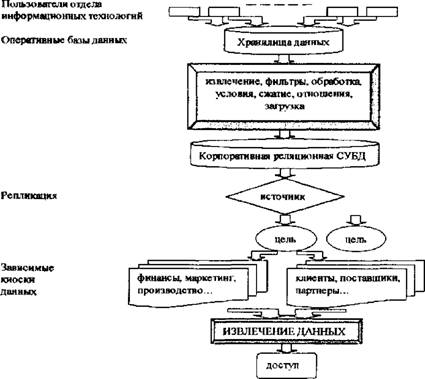
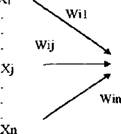
DM — набор из нескольких техник; это не просто готовое для использования решение частной деловой задачи. Это не та технология, которую можно просто купить в виде программного пакета, вся работа с которым заключается в выполнении рекомендации вида «нажмите на эту клавишу..,». «Необходимо иметь достаточную подготовку в моделировании, статистическом анализе и бизнесе, чтобы определить структуру, оценить и утвердить любую модель, является ли она моделью древа решений, нейронной сетью, дискриминантным анализом иди еще чем. Таким образом, инструмент — еще не решение»[VIII] [IX]. С целью облегчить вышеуказанную ситуацию, компанией SAS Institute была предложена методология приложения DM к любой бизнес-задаче, названная SEMMA (Sample => Explore :=> Manipulate => Model => Assess — Определение выборки =» Разведывательный анализ =⅛ Манипулирование => Моделирование => Оценивание). Внутренние потоки DM представлены на рис. 7. fΓ tr tr tr Рис 7. Внутренние потоки системы DM S ЕМ МА-подход отвечает динамической природе DM, что отвечает сложившимся в последнее время требованиям к этим системам1. Базы данных, подаваемые в системы DM, обычно имеют размеры в несколько гигабайт[X] [XI], поэтому правильная организация выборки уменьшает время разработки, снижает размерность данных и повышает качество моделей в части нахождения скрытых закономерностей[XII]. Разведывательный анализ позволяет несколько снизить неопределенность выбора метода дальнейшего анализа. Манипулирование данными и моделирование включают понятные элементы. Что касается оценивания результатов, то оно вытекает из цели DM — обеспечить лучшее объяснение проблемы и обобщить его до новых но простых данных[XIII]. Рынок систем DM активно развивается. По данным исследовательской компании Meta Group «.. почти 80% из 2000 самых больших мировых предприятий считают, что в 21 веке DM будет критическим фактором успеха в бизнесе»[XIV]. В качестве основных причин, способствующих распространению новой технологии, указываются следующие: — осознание того, что в больших по объемам БД содержатся не горы бесполезной информации, а скрытые ценные знания, характеризующие бизнес компаний и их клиентов и способные, в конечном счете, повысить эффективность управления компаниями[XV], —• развитие технологии информационных хранилищ (Data Warehousing). Решать аналитические задачи внутри существующих систем неудобно, поскольку последние по своей природе гетеро теины, функционируют на разных платформах, территориально разобщены, а главное, базы данных изначально не были ориентированы на решение аналитических задач. Гораздо удобнее иметь дело с единым информационным пространством, собрав требуемые для ана- лиза данные в центральной БД (информационном хранилище), очистив их от ошибок, приведя к единым форматам и представив в удобном для пользователя-аналитика виде1, — снижение стоимости устройств хранения информации привело к возможности хранить первичные данные с высокой степенью детализации и за длительные интервалы времени; —- уменьшение стоимости компьютеров с параллельной архитектурой позволяет распараллеливать выполнение SQL-запросов, что сильно повышает производительность систем DM; — увеличение числа сотрудников компаний, принимающих решения. Благодаря внедрению хранилищ данных корпоративная информация становится доступна широким слоям пользователей, не являющихся профессионалами в области СУБД и программирования; — обострение конкурентной борьбы между фирмами за клиента вынуждает компании улучшать качество обслуживания и предлагать все новые и новые услуги, причем основным направлением здесь являются современные информационные технологии; — переход от массового обслуживания к сегментному и индивидуальному. Индустриальная революция шла по пути массового производства, массового маркетинга и массового сервиса. Преобразования в области информационных технологий открывают возможности для индивидуального подхода. В деловой практике появился термин de-massification, обозначающий отказ от массовых форм обслуживания[XVI] [XVII]. Развертывание проектов на базе технологии информационных хранилищ и DM требует крупных инвестиций. Опыт многих организаций доказывает, что отдача от них при этом может быть весьма высокой, вплоть до 1000%. Масштабируемые хранилища данных (DATA WAREHOUSING). Масштабируемые хранилища данных[XVIII] (МХД) предназначены для сбора и управления данными с целью получить прежде недоступные ответы на вопросы. МХД особенно важны и актуальны в компаниях, чья работа связана непосредственно с обслуживанием клиентов. Одно из главных понятий — независимый киоск данных — соотносится либо по предметной области, либо по группе пользователей. Эволюция хранилищ данных выглядит следующим образом': 1. Киоски данных для каждого отдела 2 Дублирование данных о а Киоски данные Ощеп даркетинга Киоски данные Финансы Достоинствами такого метода реализации являются быстрое внедрение системы, ее невысокая стоимость и быстрая окупаемость. 3. Хранилища масштаба предприятия j ( 0 Киоски θGlu⅛√JUHl Недостаток — разрастание связей и предприятия приводит к некоторому несоответствию данных. Такой способ сбора и обработки информации позволяет пред ставлять детальные и усредненные данные, а также проводить многомерный анализ фянасьх Меркетннг Г£опмодсхво МХД используются в анализе продаж, целевом маркетинге, анализе доходов, риск- менеджменте, финансовом контроле, менеджменте, анализе продвижения. Эволюция постановки вопросов в процессе анализа данных: 1. Что произошло? 2. Что произошло? Почему это произошло? Что будет если? зграгае иредопредепинньв (влвеывьк) зявросм негр едаид енкыв запро сы здравее предопредаиишьв (лзвестюе) запросы негр едсЕщешье запросы моделирование 1 МЕТА Group, data Warehouse Marketing Trends/Opportunities, 1998. 3. Что произойдет (прогнозирова- Таким образом, доля заранее предопределенных запросов уменьшается, на смену им приходит увеличение доли непредвиденных запросов, а также появление моделирования. МХД обеспечивает интерактивные запросы, управление загрузкой, систему финансового менеджмента, планирование ресурсов, передачу знаний пользователям всех уровней1. Схема использования МХД представлена на рис. 8. Билнео-пользовйгели Рис. 8. Схема использования масштабируемых хранилищ данных Процесс интеллектуального анализа данных. Существующие программные средства DM в общем случае можно использовать с любыми источниками данных, в том числе и БД. SAS Institute, SAS Institute White Paper: SAS Rapid Warehousing Methodology, 1998. Однако целесообразнее «приложить» этот инструментарий к информационным хранилищам предприятий, в которых неоднородные данные, полученные из разных гетерогенных источников, синхронизированы, очищены и приведены к единым форматам, В общем случае информационная система на основе технологии МХД состоит из четырех компонентов — одного или нескольких серверов баз данных, ПО промежуточного слоя, обеспечивающего функционирование систем клиент/сервер, программы загрузки данных в МХД из внешних источников, которая сопровождается предварительной обработкой данных, и клиентских приложений, предназначенных для поддержки принятия решений. Процесс интеллектуального анализа данных обычно проходит в три этапа. Выбор данных. Как правило, для решения конкретной задачи нужны не все данные из МХД. Сначала необходимо выбрать то их подмножество, которое будет подвергнуто анализу. При этом возможно, потребуется объединение и фильтрация нескольких таблиц Трансформация данных. После подготовки рабочих таблиц обычно проводится предварительная обработка данных, характер которой определяется методами, применяемыми в ходе анализа. Трансформация может заключаться в удалении зашумленных данных и дублирующих записей, преобразовании типов данных, добавлении новых атрибутов и др. Анализ. Трансформированные данные последовательно обрабатываются по одной или нескольким методикам с целью извлечения требуемой информации или знаний. Классы операций и методы интеллектуального анализа данных. В ходе DM могут выполняться различные операции, реализуемые при помощи разнообразных алгоритмов. В основе большинства из них лежит мощный аппарат современной математической статистики. Методы DM условно делят на два класса: операции проверки гипотез и операции поиска зависимостей, направленные на автоматическое выявление закономерностей или правил, которым подчиняются данные информационного хранилища, К недостаткам процедур первого типа можно отнести ограниченность анализа жесткими рамками заранее указанной гипотезы; проблема заключается в том, что другие возможные корреляции попросту выпадут из рас- -41 - смотрения. Во втором случае системы DM самостоятельно обрабатывают информацию с целью обнаружения внутренних закономерностей. Полученные результаты часто оказываются весьма неожиданными и ведут к нетривиальным выводам. Комбинируя операции двух типов, возможно реализовать самые замысловатые стратегии анализа. Рассмотрим известные операции DM. — проверка гипотез. Операции этого типа выполняют генераторы отчетов, системы обработки SQL-запросов, приложения многомерных БД и модули статистического анализа. — генерация отчетов и обработка запросов. Ее основное назначение — подтвердить правильность гипотез, сформулированных пользователем, который последовательно генерирует несколько разных и/или уточняющих SQL-запросов, призванных помочь в подтверждении правильности исходного предположения. Последовательность выполненных запросов и правила построения таблиц и графиков образуют так называемый сценарий анализа, который впоследствии можно распространять среди других пользователей компании. — многомерный анализ. Чем серьезнее вопросы, формулируемые пользователями, тем сложнее для восприятия и отладки становятся SQL-запросы, тем заметнее падает производительность их обработки. Чтобы этого не происходило, производят перегруппировку «сырых» данных, создавая несколько новых таблиц, каждая из которых отражает определенное измерение (время, рынки, продукты, клиенты и т. д.). — статистический анализ. Простейшая статистическая обработка возможна при работе с данными на уровне SQL-запросов. Однако для выполнения более содержательного анализа требуются специализированные средства, которые не только поддерживают соответствующие методы анализа, но и имеют наглядные средства визуализации результатов. — поиск зависимостей. К этому типу операций относятся прогнозное моделирование, анализ связей, сегментация данных и идентификация отклонений. — прогнозное моделирование. Благодаря бурному развитию различных методов автоматического построения моделей (методы индукции, нейронные сети) прогнозное моделирование стало самым распространенным типом операций DM Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить математическую модель, адекватно описывающую эту динамику, есть вероятность, что можно предсказать и поведение системы в будущем. — анализ связей. Здесь требуется найти специфические связи между различными записями в БД, Классические алгоритмы выявления связей базируются на статистических методах корреляционного и регрессионного анализов. — сегментация баз данных Разбиение записей БД на несколько групп проводится в качестве предварительного этапа с целью сузить поиск и сократить период дальнейшей обработки. К подготовленным таким образом коллекциям данных применяются другие методы —- прогнозного моделирования или анализа связей. — идентификация отклонений. Цель этой операции, — во-первых, выявить данные, которые не входят ни в один из имеющихся сегментов, а во-вторых, установить, являются они «шумом» или отражают пока неизвестные закономерности. Применяемые здесь алгоритмы основываются на методах дисперсионного анализа. Существующие операции DM поискового типа поддерживаются большим числом различных методик: одна и та же операция может быть реализована различными способами: — индукция. Это процесс автоматической генерации классификационной модели на основе специально подготовленных тестовых данных, содержащихся в БД, Индуцированная модель выглядит как совокупность образцов данных, по которым идентифицируется новый класс. Однажды созданную модель можно применять в дальнейшем для обнаружения классов среди новых записей. Существует два типа индукции: нейронная и символическая (древо решений). Индукционные методы позволяют построить качественные модели даже в случае, когда обучающие данные неполны или сильно зашумлены. Кроме того, они способны накапливать знания, что существенно улучшает качество вновь генерируемых моделей. — поиск ассоциаций. Заключается в выполнении некоторой операции с набором записей для определения степени «общности» между элементами коллекции. Выявленные зависимости выражаются посредством правил, например: «89% всех записей, в которые входят элементы А, В и С, включают также элементы D и Е». Поиск ассоциаций предполагает выявление корреляций в исходных данных и последующее интервальное оценивание. —- кластеризация. Это процесс разбиения БД на ряд сегментов (кластеров), объединяющих данные, имеющие общие характеристики. Результаты кластеризации применяются двояко: для подведения суммарных итогов по кластерам и в качестве входных данных для какого- либо другого метода анализа. Основное интерес и отличие от традиционных методов заключается в отсутствии обучающей выборки и каких-либо априорных сведений о структуре данных. В последние годы, помимо многочисленных традиционных методов, для проведения кластерного анализа все шире применяются нейронные сети. — нейронные сети. Архитектура нейросети включает взаимосвязанные рабочие элементы нейроны, каждый из которых генерирует выходной сигнал в ответ на несколько входных. Выход элемента является входом для других. Каждый вход получает вес, который корректируется в процессе обучения сети. Обучение сводится к подбору таких весов, при которых нейросеть безошибочно распознает эталонную выборку. Поскольку каждый элемент нейросети частично изолирован от своих соседей, у нейросетевых алгоритмов имеется хороший потенциал для распараллеливания вычислений. С помощью алгоритмов нейросетей можно решать многие задачи DM: прогнозировать поведение объекта, основываясь на данных о его динамике в прошлом, производить факторный анализ, выявлять аномалии и сходства. — генетические алгоритмы. Были предложены в начале 70-х годов Джоном Холландом с целью имитации эволюционных процессов в живой природе. Холланд предпринял попытку формализовать законы эволюции и использовать их для решения задач оптимизации. С помощью генетических алгоритмов решены многие прикладные задачи. В системах DM генетические алгоритмы используются для поиска зависимостей. Модели представления знаний. Часто вопрос выбора модели представления знания і сводят к обсуждению баланса между декларативным и процедурным представлением[XIX]. Раз личие между ними можно выразить как различие между «Знать, что» и «Знать, как». Процедурное основано на предпосылке, что интеллектуальная деятельность есть знание проблемной среды, вложенное в программы, т.е знание о том, как можно использовать те или иные сущности. Декларативное основано на предпосылке, что знание неких сущностей не имеет глубоких связей с процедурами, используемыми для обработки этих сущностей. Основное достоинство декларативного по сравнению с процедурным заключается в том, что в нем нет необходимости указывать способ использования конкретных фрагментов знания. Это позволяет по разному использовать одни и те же факты. Задачи компьютерных систем поддержки принятия решений. Принятие решения в большинстве случаев заключается в генерации возможных альтернатив решений, их оценке и выборе лучшей альтернативы. Принять «правильное» решение — значит выбрать такую I альтернативу из числа возможных, в которой с учетом всех разнообразных факторов и про- тиворечивых требований будет оптимизирована общая ценность. Неопределенности являются неотъемлемой частью процессов принятия решений Компьютерная поддержка процесса принятия решений так или иначе основана на Р формализации методов получения исходных и промежуточных оценок, даваемых лицом, принимающим решения, и алгоритмизации самого процесса выработки решения. Увеличение объема информации, усложнение решаемых задач, необходимость учета большого числа взаимосвязанных факторов и быстро меняющейся обстановки требуют использовать вычислительную технику в процессе принятия решения. В связи с этим появился новый класс вычислительных систем — системы поддержки принятия решений (СППР). Термин «система поддержки принятия решений» появился в начале семидесятых годов. За это время дано много определений СППР1. Например, она определяется следующим образом[XX] [XXI]: «Системы поддержки принятия решений являются человеко-машинными объектами, которые позволяют лицам, принимающим решения использовать данные, знания, объективные и субъективные модели для анализа и решения слабоструктурированных и неструктурированных проблем». В этом определении подчеркивается предназначение СППР для решения слабоструктурированных и неструктурированных задач. К первым относятся задачи, которые содержат как количественные, так и качественные переменные, причем качественные аспекты проблемы имеют тенденцию доминировать[XXII]. Неструктурированные проблемы имеют лишь качественное описание. Далее СППР дается такое определение[XXIII]: «Система поддержки принятия решений — это компьютерная система, позволяющая ЛПР сочетать собственные субъективные предпочтения с компьютерным анализом ситуации при выработке рекомендации в процессе принятия решения». Основное здесь — сочетание субъективных предпочтений ЛПР с компьютерными методами. Наконец, СППР определяется «как компьютерная информационная система, используемая для различных видов деятельности при принятии решений в ситуациях, где невозможно или нежелательно иметь автоматическую систему, полностью выполняющую весь процесс решения»[XXIV]. Определения не противоречат, а дополняют друг друга, полно характеризуя СППР. Построение агентных систем. Объемы хранимой и обрабатываемой информации продолжают расти, в связи с чем ставится вопрос о том, чтобы передать некоторые функции обработки этой информации интеллектуальным системам. При этом подобные системы должны самостоятельно принимать информацию, обрабатывать ее, принимать решения о ее дальнейшем продвижении, обеспечивать это продвижение. Изначально, подобными вопросами занимаются Cl IIIP. Данные системы разрабатываются в двух направлениях. Первое состоит в предварительной обработке потока информации, выявлении зависимостей в этом потоке, обобщении. В результате работы такой системы пользователю выдается не вся информация, а только та, которая его интересует, либо весь поток обобщенной информации. Поступившая информация накапливается в БД и при желании можно получить доступ и к ней. Второе направление состоит в применении методов искусственного интеллекта Такая система анализирует ситуацию, после чего выдает свои рекомендации по ней. При необходимости пользователь может ознакомиться с данными и путями логического вывода и принять свое собственное решение. Второй класс систем обычно работает с небольшим количеством входной информации, но очень хорошо показывает себя в случаях, когда время, отведенное на принятие решения, ограничено и методы принятия решения в большей степени эмпирические. Однако зачастую необходимо, чтобы система могла самостоятельно влиять на внешний мир. Итак, задачей, выполняемой подобными системами, должно быть автоматическое реагирование на входную информацию. Под агентом будем понимать самостоятельную программную систему, имеющую возможность принимать воздействие из внешнего мира, определять свою реакцию на это воздействие и осуществлять эту реакцию[XXV]. Под внешним миром здесь понимается среда, окружающая агента. Перечисленные и многие другие задачи агенты могут выполнять без использования методов искусственного интеллекта. Однако ряд задач просто не может быть решен без них. Под интеллектуальным агентом будем понимать агента, который обладает рядом знаний о себе и окружающем мире и поведение которого определяется этими знаниями Итак, наличие искусственного интеллекта означает, что агент должен некоторым образом хранить свои знания. За историю искусственного интеллекта было разработано множество методов представления знаний. Однако наиболее распространенными на данный момент являются продукции (правила вида «если ... то ...») и нейронные сети. Первые завоевали свой успех благодаря простоте понимания, формализации и реализации, Вторые — тем, что нет необходимости формализовать знания и заносить их в базу, а достаточно обучить сеть. И те, и другие дают вполне неплохие результаты. При построении агентных систем следует помнить о следующих трудностях. Работа агентов происходит в реальном времени. Предобработка информации задерживает ее поступление в блок, отвечающий за планирование действий. Кроме того, системе может потребоваться и время на реакцию, поэтому, несмотря на развитие компьютерной техники, искусственный интеллект все еще нуждается в быстрых методах принятия решений. Исключением будут ситуации, когда время реакции гарантированно много больше, чем время принятия решения, либо если ведется моделирование. Однако в последнем случае моделироваться может система, время на принятие решения в которой будет критично. Агентная технология, по мнению многих специалистов в области искусственного интеллекта, является перспективной областью исследования. Решение таких задач поможет автоматизировать и интеллектуализировать обработку информации и, как следствие, ускорить и улучшить эту обработку. Нейронные сети — основные понятия и определения. В истории исследований в области нейронных сетей, как и в истории любой другой науки, были свои успехи и неудачи. Кроме того, здесь постоянно сказывается психологический фактор, проявляющийся в неспособности человека описать словами то, как он думает. Способность нейронной сети к обучению впервые исследована Дж. Маккалоком и У. Питтсом. В 1943 году вышла их работа «Логическое исчисление идей, относящихся к нервной деятельности», в которой была построена модель нейрона, и сформулированы принципы построения искусственных нейронных сетей. Крупный толчок развитию нейрокибернетики дал американский нейрофизиолог Френк Розенблатт, предложивший в 1962 году свою модель нейронной сети —- персептрон. Воспринятый первоначально с большим энтузиазмом, он вскоре подвергся интенсивным нападкам со стороны крупных научных авторитетов. И хотя подробный анализ их аргументов показывает, что они оспаривали не совсем тот персептрон, который предлагал Розенблатт, крупные исследования по нейронным сетям были свернуты почти на 10 лет. Несмотря на это в 70-е годы было предложено много интересных разработок, таких, например, как когнитрон, способный хорошо распознавать достаточно сложные образы независимо от поворота и изменения масштаба изображения. Разработка метода обучения обратного распространения ошибки переломило ситуацию вокруг нейросетей, дав мощнейший толчок дальнейшим исследованиям. Этот момент — одна из важнейших вех развития всех разработок в области искусственного интеллекта. В 1982 году американский биофизик Дж. Хопфилд предложил оригинальную одноименную модель нейронной сети. В последующие годы было найдено множество эффективных алгоритмов: сеть встречного потока, двунаправленная ассоциативная память и др. Нейронные сети могут быть реализованы двумя путями: программная модель НС и аппаратная. Большинство сегодняшних нейрокомпьютеров представляют собой просто персональный компьютер, в чей состав входит дополнительная нейроплата. В работе они не рас сматриваются. у суммирование нелинейное преобразование у, =,m> vi÷∑⅞xj- Рис. 9. Работа нейрона В основу искусственных нейронных сетей положены черты живых нейронных сетей, позволяющие им хорошо справляться с нерегулярными задачами Рабочим элементом любой нейронной сети является нейрон. Работа нейрона (рис. 9) заключается в следующем: вычисляется скалярное произведение между входами и весовым вектором; этот результат передается через передаточную функцию, после чего получается выходной сигнал вершины; выходной сигнал передается к следующему слою, пока не будет достигнут выходной слой сети. Основные парадигмы нейронных сетей включают в себя следующие: - Обратное распространение • Обобщенное дельта-правило; • Правило нормализованного совокупного обучения; • Delta-Bar-Delta обучение (DBD); • Расширенное Dclta-Bar-Delta обучение (EDBD); • QutckProp; • MaxProp, • Fast back-prop, • Спуск по отпряженным градиентам; ■ Levcπberg-Marquardt. — Нейронная сеть общей регрессии; — Модульная нейронная сеть; — Вероятностная нейронная сеть; — Сеть функции радиального базиса: • Moody-Darkeπ сеть, использующая динамические к-среднее; • Противораспросгринсние. — Сети пополнения: • Направленное случайное исследование (DRS); — Теория адаптивного резонанса: • ART 1; •Нечеткий ARTMAP. — Самоорганизующиеся карты: — Смешанные сети; — Исторические сети: • Adaline; • Boltzmann; • Brain-Statc-ln-a-Statc; • Изучение категорий; • Hopfield, • Madalinc; • Percept топ; • SPR. При проектировании сети необходимо точно определить следующую информацию: число элементов входа; число скрытых слоев; число элементов в каждом из скрытых слоев; число выходных элементов; соединения элементов; передаточные функции. При разработке нейросетевых моделей предпринимаются следующие шаги; формули рование идеи модели (определение входных и выходных переменных); накопление данных; обработка и форматирование данных; создание модели нейронной сети; обучение сети; анализ обученной сети; проба альтернативных проектов. Сложная формализуемость задач (иеформализуемость) Отсутствие линейных зависимостей; Сложно сть*с ама-по -себе; Нерсдуцируемость к простому. Теорія систем и системного анализа Многомерность данных; Рассмотрение системы как одного целого; Свойства системы не просто сумма свойств ее элементов; Система является подсистемой. Компьютерные системы поддержки принятия ре ГОЄНИЙ Развитие информационных технологий Теорія принятия решений Модели представления данных Перенос интереса с > из «зяать-что» 9 9 Ускорение доступа к любой информации (Iflternet) Рис. 10. Взаимосвязь компонентов современного состояния ситуации в области анализа и прогноза данных гостиничных предприятий Одно из важнейших свойств нейронной сети — способность к самоорганизации, са- моадагттации с целью улучшения качества функционирования Это достигается обучением сети, алгоритм которого задается набором обучающих правил. Обучающие правила определяют, каким образом изменяются связи в ответ на входное воздействие. Итак, общая схема взаимосвязей описанных выше компонент управления и анализа деятельности предприятия представлена на рис. 10. На нем отражено мнение автора о сложившейся на текущий момент ситуации и предпосылках вокруг прогнозирования на предприятиях индустрии гостеприимства. Из рисунка видно, что главными причинами становятся увеличение объема информации, необходимость в ускорении ее обработки и параллельное всему этому развитие инфор мационных технологий, которые помогают гостиничному предприятию, как и любому другому, справиться с первыми двумя причинами. В центр рисунка поставлены нейронные сети. Сделано это по причине способности их довольно успешно справляться с требованиями окружающих элементов, что является довольно редкой особенностью для остальных методов, способных справляться с элементами только по отдельности. Кроме того, можно сказать даже больше: использовать надо не просто ту или иную единичную нейронную сеть, а целые комплексные модели, состоящие из нескольких видов нейронных сетей, результаты одной из которых являются входными данными для другой.
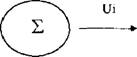

Еще по теме Управление данными:
- Калибровка средними отраслевыми данными
- Контроль за данными
- Глава 4.3 РАБОТА C ДАННЫМИ
- РАБОТА C ДАННЫМИ C ПОМОЩЬЮ ФИЛЬТРОВ
- Глава 5.6 ОБМЕН ДАННЫМИ МЕЖДУ ПРИЛОЖЕНИЯМИ
- Электронный обмен данными (EDI, electronic data interchange)
- 18.1. Менеджмент управление персоналом: персонал предприятия как объект управления;место и роль управления персоналом в системе управленияпредприятием; принципы управления; трудовой потенциал как экономическая категория и его место в системе оценок общественного производства
- Управление иерархией валютФинансовое управление как вид религиозного управления
- Отчет о прибылях и убытках форма № 2: значение, структура, определение понятий отдельных показателей: выручка, доходы, расходы, прибыль, убыток, себестоимость проданной продукции и др., содержание, источники информации, порядок составления, взаимоувязка с данными других форм бухгалтерской отчетности.
- Вопрос 13. Методы и формы управления финансами. Объекты и субъекты управления
- Методические подходы к оценке эффективности «управления по результатам» в публичном управлении
- Содержание, порядок составления и значение бухгалтерских отчетов «Отчет об изменениях капитала» (форма № 3) и «Приложение к бухгалтерскому балансу» (форма №5). Взаимоувязка их данных с данными бухгалтерского баланса (форма № 1).
- Управление финансами: понятие, объекты и субъекты управления, функции
- 3. Объекты и субъекты управления, цели управления
- 3.1. Сравнительный анализ эффективности управления по результатам в публичном управлении на региональном уровне
- Управление предприятием: задачи, функции и методы управления.